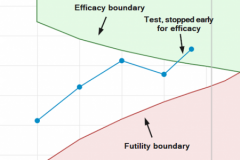
“I didn’t fail the test, I just found 100 ways to do it wrong.” Benjamin Franklin
In marketing, A/B testing is a technique for measuring the effect of web page changes on a performance metric, such as click through Rate, sign-ups, purchases, etc., on all of your visitors or a specific segment. Marketers have been using A/B testing for a long time to improve revenue and conversion rates. Nevertheless, the reality is that badly performed tests may produce invalid results, which may lead to false observations or unnecessary website implementations and changes. To avoid getting false results, we should arm ourselves with a set of ideas and approaches, which protect the validity of the process.
When running an A/B test, using a valid methodology is crucial for our ability to rely on the test results to produce better performance long after the test is over. In other words, we are trying to understand if tested changes directly affect visitors’ behavior or occur due to random chance. A/B testing provides a framework that allows us to measure the difference in visitor response between variations and, if detected, establishes statistical significance, and to some extent causation.
The basic methodology, called hypothesis testing, is the same used to prove if medical treatments actually work or if hot weather results in increased ice cream sales. But what makes a successful A/B test? How can we trust the results? The difference between running a successful A/B test or an unsuccessful A/B test relies on the methodology and validity of the data.
Before we dive into more advanced techniques, let’s get familiar with the basic terms.
A/B Testing Glossary / Statistical References

1. Claim
Usually referred to as hypothesis, a claim is a change and effect statement, that may, or may not be true, (hopefully) based on initial or limited evidence. In A/B testing, the claim is always made about the visitor and his or her reaction to changes. For example: changing the text of the call-to-action button from “Submit” to “Sign up for a FREE trial” will increase sign-up conversion rates.
2. Correlation
A correlation means an associated relationship between the impression of a web page variation and the visitor’s reaction to it. This doesn’t mean there is a causal connection between the two.
3. Causation
In statistics, the term “causation” stands for a causal relationship between two random variables, when one changes because of the other, with different causation models (or explanations). Unfortunately, although we’re able to measure correlation in web page A/B testing, we can’t actually deliver a definite proof of causation between a variation change, and a change in user response. There are several possible reasons for that, for example: spurious relationships, where there’s an underlying factor involved that wasn’t measured. Another possible explanation is that there’s always room for random chance.
4. Statistical significance (or confidence level)
In A/B tests, statistical confidence sometimes referred to as “chance to beat original,” measures the probability that the difference in the measured performance between the different variations is real and not due to chance alone. A 95-percent confidence level means that there’s only a five percent chance that the numbers are off. But even a 99-percent confidence level doesn’t necessarily mean that the results are absolutely reliable. It only means that the error rate is much smaller (one percent in this case), and that all models’ assumptions are indeed valid. We should also keep in mind that a statistical significance is a function of sample size.
5. Sample size
Sample size represents the number of visitors who have been part of your test. Generally speaking, the larger the sample size, the more reliable the results will be (the more statistical power your test has). That being said, choosing the right testing method, in terms of number of variations (A/B test versus multivariate test with multiple variations) is crucial for obtaining results fast.
Hold Your Horses! Make Sure Your Tests Are Valid
One of the fundamental goals of statistical inference is to be able to make general conclusions based on limited data. When performing web page A/B tests, the scientific phrase “statistically significant” sounds so definitive that many marketers and users of A/B testing solutions rely on it to conclude the observed results of the tests. Sometimes, even a tiny effect can make a huge difference, eventually altering the “significance” of the conclusions. Sticking to a strict set of guidelines will deliver more reliable results, and thus more solid conclusions.
10 Golden Tips For Running Successful A/B Tests
1. High confidence level – Try to get as close to a 99% confidence level as possible in order to minimize the probability of getting the wrong conclusions.
2. Be patient – Don’t jump to conclusions too soon, or you’ll end up with premature results that can backfire. You know what? Stop peeking at the data as well! Wait until the predefined sample size is reached. Never rush your conversion rate optimization, even if your boss pushes you to get results too fast. If you can’t wait and need potentially faster results, I advise you to choose tools that can actually achieve reliable results faster, as a result of a mathematical prediction engine, or a multi-armed bandit approach. That being said, there’s no real magic. Be patient.
3. Run continuous or prolonged tests for additional validations – If you don’t trust the results and want to rule out any potential errors to the test validity, try running the experiment for a longer period of time. You’ll get a larger sample size, which will boost your statistical power.
4. Run an A/A test – Run a test with two identically segmented groups exposed to the same variation. In almost all cases, if one of the variations wins with high statistical confidence, it hints that something technically may be wrong with the test. Most A/B testing platforms use a standard p-value to report statistical confidence with a threshold of 0.05. This threshold is problematic, because when not enough data is collected, these tools may reach statistical significance purely by chance – and too soon (this is often due to the fact that not all assumptions of the model are valid).
5. Get a larger sample size or fewer variations – If you’re able to run the test on a larger sample size, you will get higher statistical power, which leads to more accurate and more reliable results. On the other hand, if you’re using more than two variations and don’t have enough traffic volume for proper, valid results, try reducing the number of variations.
6. Test noticeable changes – Testing minor changes to elements on your site may get you farther away from any statistically significant conclusions. Even if you’re running a high-traffic site, test prominent changes.
7. Don’t jump into behavioral causation conclusions – As marketers, we often base decisions on our intuition regarding the psychology of the visitor. We believe we know the reason for the visitor’s positive/negative reaction to variations. A/B testing comes in to help us rely a bit less on our instincts and a bit more on concrete evidence. Good marketing instincts are useful for creating testing ideas and content variations. The A/B test will take us the extra mile by enabling us to base our instincts on data.
8. Don’t believe everything you read – Although reading case studies and peer testing recommendations is great fun, find out what really works for you. Test for yourself. Remember that, sometimes, published statistics tend to be over optimistic, and not representative.
9. Keep your expectations real – More often than not, following the end of a successful A/B test, there’s an observed reduction in the performance metrics of the winning variation. This phenomenon is called regression toward the mean, and it is not something that can be quantified and corrected in advance. So, to avoid making the wrong conclusions, lower your expectations once a test is over.
10. Test continuously and never stop thinking and learning – The environment is dynamic. So should be your ideas and thoughts. Evolve and think forward. Remember that the downside of all traditional A/B testing tools is that, eventually, these tools direct you to make static changes to your site, which may or may not fit all of your potential users in the long run. In other words, you’re not necessarily maximizing your conversion rates by serving only one winning variation to all of your visitor population or by conducting short-term tests. Some tools (like the one we offer at Dynamic Yield) allow you to personalize the delivery of variations based on machine learning predictions (that require a relatively large amount of data) instead of waiting for one variation to win globally. With these tools, instead of catering your website to the lowest common denominator, you can actually deliver a better user experience by dynamically choosing to display the right variation to the right users.
Closing Thoughts
Let me finish by saying that although I provided some necessary statistical references in this article, I’m not a statistician. I am a Marketer and a Conversion Rate Optimizer. I hope the ideas reflected in this article will help you improve your A/B testing techniques for better decision making and conversion rates.